25年的春节,深度求索(deepseek)给AI圈乃至全国人民都带来一个很厉害的AI模型。Deepseek R1,一个仅用600万不到的成本训练出来的大模型做到了和全球最先进的 OpenAI O1 模型不相上下的效果。这背后带来的变化有无数博主春节加班给大家分享,我这里就不班门弄斧了,不仅了解的信息比别人少,文笔也远不如那些头部自媒体。但作为一个技术人,分享一个本地的部署和玩法还是OK的。
所以本期的内容是分享 Deepseek 的本地部署和连接 SillyTavern 使用。对了,这个过程对电脑性能有一定要求,如果没有一张较强的显卡(推荐是3070及以上,低一些可能也行但估计体验较差),不推荐尝试。
在我动手前,B站上就已经有铺天盖地的视频教程出现了,包括现在我写下这篇文章时,连 deepseek 连接 SillyTavern 的视频教程也出现了。差点想删除草稿了,但想到我折腾时搜不到东西,最后靠切换成英语关键词搜索才在 medium 平台上看到一篇资料,也许文本还是有和视频教程不同的地方吧,希望能帮助到后来者。
关于 Deepseek
在开始前,还是想再多说两句 deepseek。
很早我就关注到这家公司了,它就是国内 AI 大模型价格战的发起方,随着它的V2版本发布,它把价格直接降到 1 元每百万 token ,中文粗略计算可以直接除以 2,也就是 1 块钱买 AI 输出 50 万字,这简直太便宜了。随着它的降价,百度、阿里、字节、腾讯纷纷降价。但从我了解的信息,深度求索的大模型靠 MoE 方案,本身成本就是非常低,即使是 1元/百万token 的费用,深度求索公司依然是盈利的,这让我感觉到不可思议。相比之下其他家的降价则更像是一种补贴,用亏损换市场的行为,后期再靠垄断割韭菜,不知道这是否算一种路径依赖……
同时深度求索公司规模特别小,从它们的文档就能感觉出来,特别简短,甚至可以说是简陋,就像是连个写文档的人都抽不出来的感觉。此外它们家的模型的开发成本是最低的,就是注册,申请API Token,按文档调用,通了。和OpenAI的使用体验一模一样,简洁、可靠。
作为对比,百度、阿里、腾讯、字节的模型都是在它们的云服务公司下提供,如果你尝试接过就知道我在说什么,光是产品介绍就一堆。然后要接入,先各种订购、权限包,然后费用方面又是看得眼花缭乱,最后拿到 Token 后,还会画蛇添足给你准备一堆 SDK ,而这些 SDK 又不好用,十分怀疑是外包写的。
OK 以上的吐槽到此为止,接下来进入正文。
安装 SillyTavern
SillyTavern(字面意思翻译过来叫愚蠢的小酒馆)是一个 Web UI,可让您创建上传和下载独特的角色,并通过 LLM 后端服务与这些角色进行沟通对话,可以理解成是一种角色扮演,这类的应用在国内外其实都已经屡见不鲜了,甚至我记得最先盈利的好像就是这类角色扮演应用。在本教程中,我将展示如何在Windows上使用本地部署的 Deepseek 模型和 SillyTavern 联合使用。
SillyTavern 的地址是 https://github.com/SillyTavern/SillyTavern
第一步安装必要的依赖 git 和 Node,如何安装建议直接搜索或者询问任意AI,资料太多本文不赘述。
git 建议配置 SSH key 并上传公钥到 GitHub ,因为国内特殊的网络环境,https 很可能拉不到代码,SSH 协议会好很多。
进入命令行,找一个非 Windows 系统目录的地方(比如用户文件夹、文档下开个目录之类) clone 下来仓库。
git clone git@github.com:SillyTavern/SillyTavern.git
此时能看到对应文件夹下出现了 SillyTavern 文件夹,进去后双击 Start.bat 。
如果一切顺利,大概能看到下面的截图,运行完成后会自动打开浏览器对应页面。
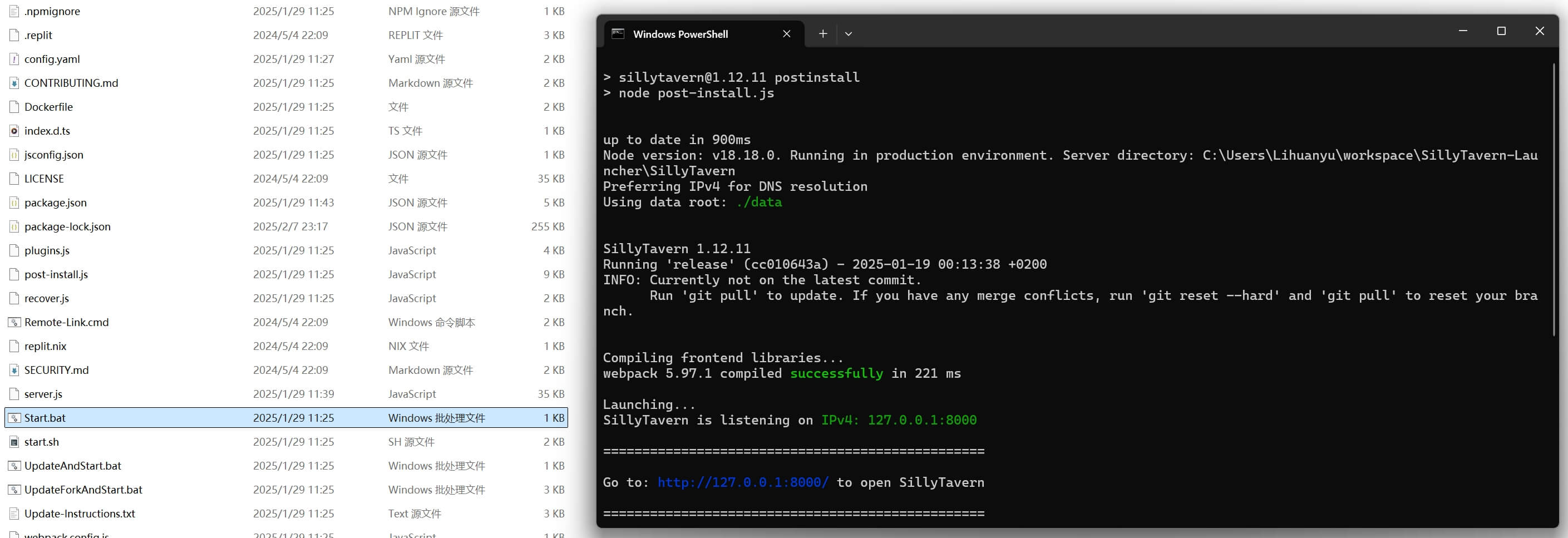
OK,网页可以先放着,这只是一个UI界面,接下来我们来部署本地的LLM服务。
通过 Ollama 使用 Deepseek R1
在B站里的教程比较普遍的就是教通过 Ollama 本地部署 DeepSeek R1 模型,实践下来发现确实简单得可怕。安装 Ollama ,搜索模型,复制命令,执行。
Ollama 是一个开源的本地化工具,旨在简化大型语言模型(LLMs)的部署和使用。它允许用户在个人电脑或服务器上直接运行各种开源模型(如 Llama 2、Mistral、Phi-2 等),无需依赖云端服务,适合开发、测试和研究场景。
Ollama 官网地址:https://ollama.com/

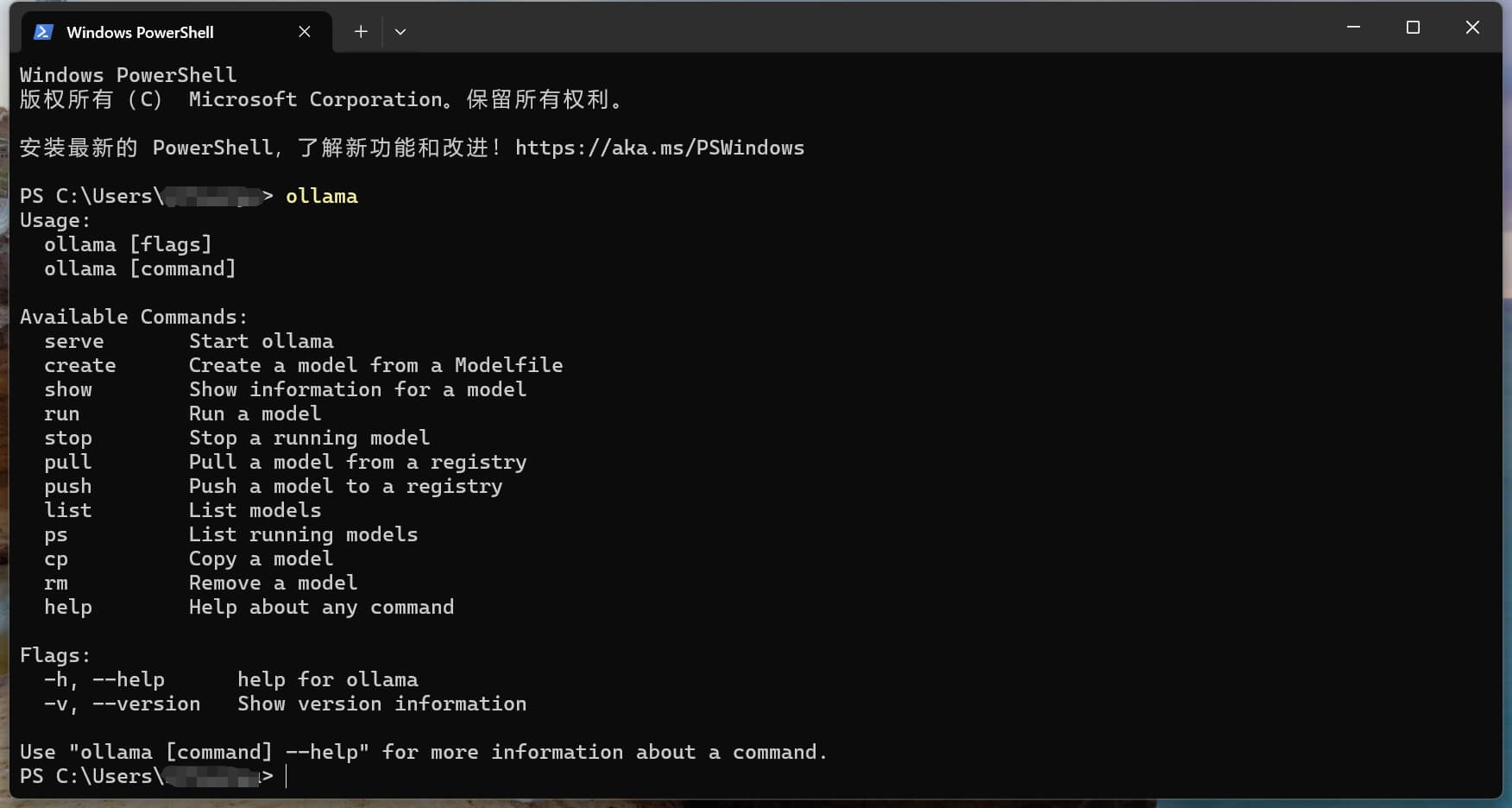
页面很简洁,直接点 Download 下载即可。下载安装完成后可以看到右下角托盘区多了一个羊驼的 Logo,表示 Ollama 服务已启动,同时会有命令行启动,输入 ollama 可以看到如下界面:
接下来在 Ollama 的网页顶部的搜索里输入 deepseek 找到 R1 模型。
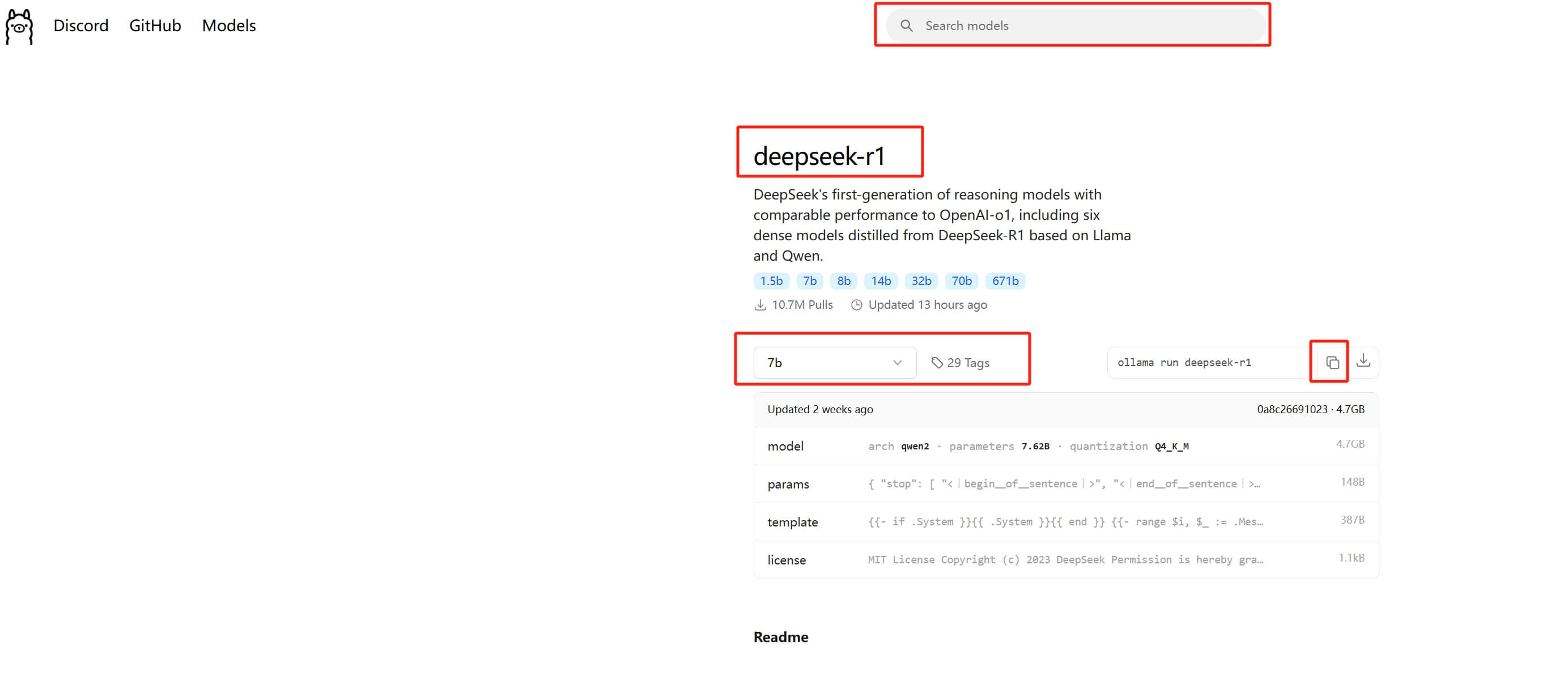
这里需要根据自己电脑的配置决定选什么版本的模型,在机器学习模型里,参数规模会用B表示十亿(Billion),参数量的差异会影响模型的能力,更大的模型通常能处理更复杂的任务,但需要更多的计算资源和内存。比如,70B的模型比7B的模型大10倍,可能在理解上下文、生成文本的准确性上有显著提升,但推理速度会慢很多,并且需要更高端的硬件支持。一般选择一个模型体积小于你显存容量的版本,可以比较流畅地运行。
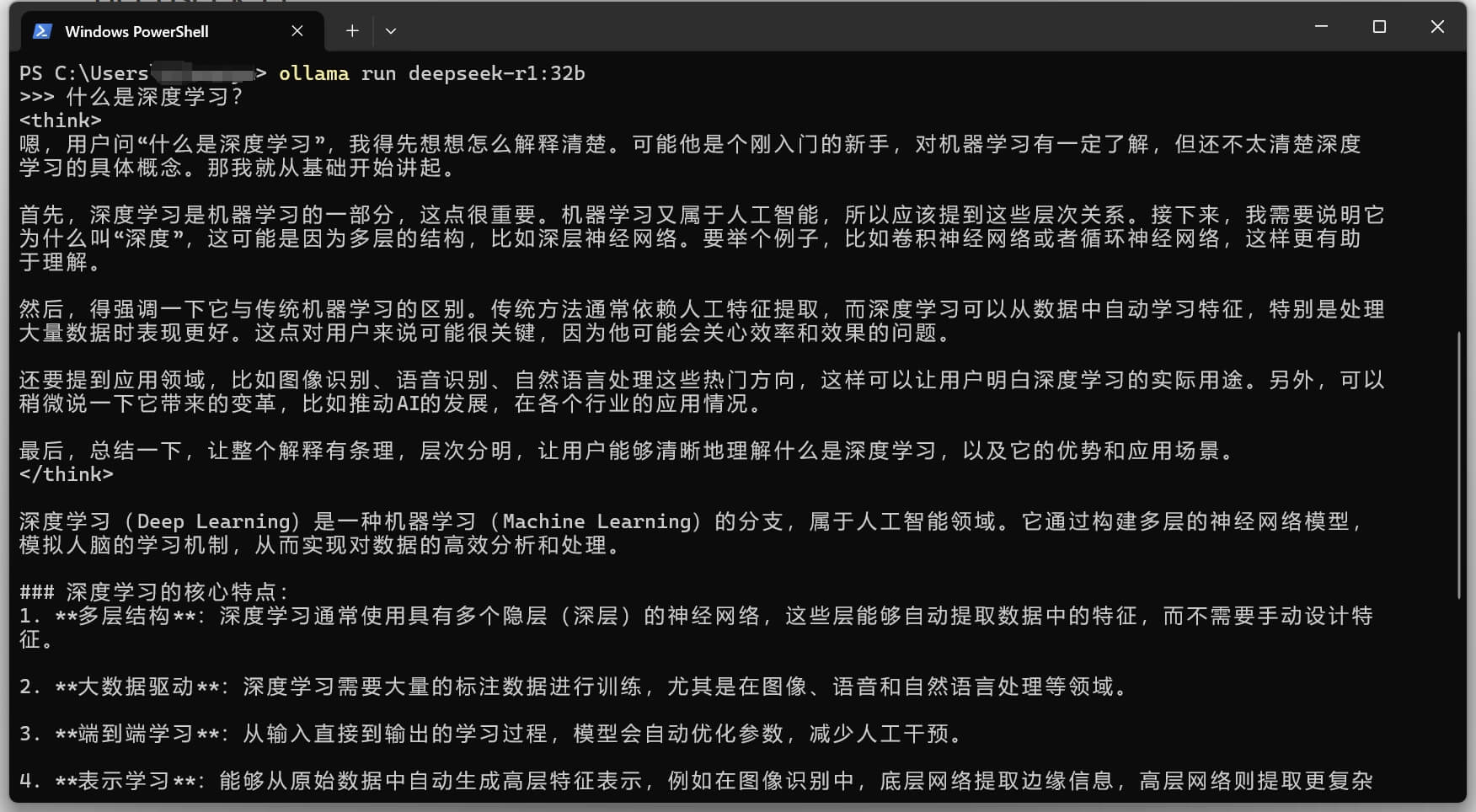
比如我的显卡 GTX 4090 有 24GB 显存,所以可以流畅运行 32B 版本(模型体积20GB)。在控制台输入复制过来的命令 ollama run deepseek-r1:32b ,首次运行会自动下载模型文件需要一定时间(耗时取决于你的网络情况),下面的截图里已经不是首次运行,模型文件是已经下载好的状态:
好了,现在我们 LLM 推理服务也就位了,接下来可以把两者连起来了。
本地部署仅供学习、测试使用,因为本地的硬件成本限制,普遍跑的都是 7B - 32B 的模型,这和 deepseek 官方网页与官方 API (满血版,是671B级别的超大规模模型)的表现差异极大,真正的生产场景应该优先考虑线上版本。
连接使用
小酒馆运行后弹出的网页如图:
点击顶部红色的插头图标,进行对应的配置:
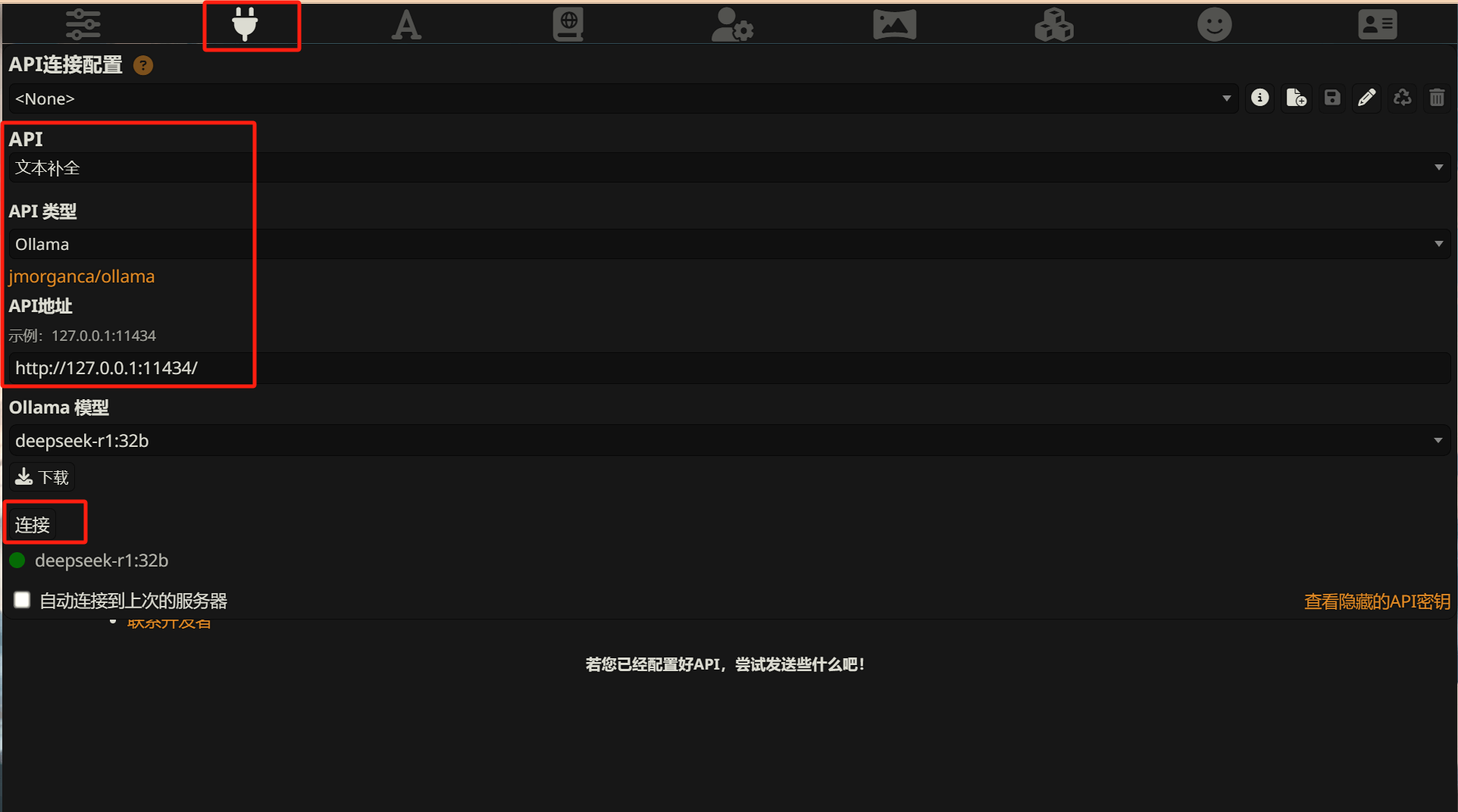
出现绿色的模型版本即表示正确连接了。接下来就可以选择角色卡进行聊天了,相关的一些设定参考网上关于酒馆的配置教程,角色卡也有相关的社区分享可以直接下载使用。
其它服务
除了小酒馆,普通的问答使用也可以另一个插件叫 Page Assist ,是一个Chrome插件,搜索即可找到,这个插件还包含了联网搜索之类的工程能力。
但缺点在于,它是专为 Ollama 适配的,如果想用别的 LLM 服务就不太方便了。
Ollama 虽然方便,但过于简洁了,如果想找更多的模型自行体验玩耍,可以考虑使用 koboldcpp ,或者 LM studio 。